1. 스레드 스케줄링
1) Contention Scope
코아가 1개라 가정하고 Contention Scope를 설명한다.
프로세스안에 스레드들이 존재하는데 스레드들을 스케줄링하는 것은 LWP(Light Weight Process)이다.
이는 kernel thread 에 존재하며(kernel thready의 개수만큼 존재) user Thread를 어떤 kernel thread로 연결할지 스케줄링해주는 프로세스이다.
예를 들어 사용자 모드의 스레드가 3개 커널도 3개(이는 LWP가 3개임을 의미)있다고 해보자.
사용자 모드에 있는 스레드3개 를 3개의 LWP3에 할당한다. 그리고 이 LWP를 스케줄링하여 CPU 자원을 할당하는 것이다.
여러 프로세스들 중 CPU 자원을 할당해서 실행하는 것이 목적이다. CPU의 자원을 할당하기 위해 이 과정에서 크게 2가지 level의 스케줄링이 존재하는데
① PCS(Process-contention scope)
사용자 프로세스에 존재하는 스레드들을 LWP에 매핑하기 위한 스케줄링으로 프로세스 안에서 경쟁하는 것이다. PCS는 프로그래머가 스레드의 우선순위를 지정할 수 있고 지정된 스레드의 우선순위에 따라 LWP로 매핑된다.
② SCS(system-contention scope)
커널에서 수행하는 스케줄링이다. LWP를 실제로 하드웨어 CPU 자원에 할당을 하기 위한 스케줄링이다. SCS는 OS가 처리한다.
2) Multiple-Processor Scheduling
지금까지 이글의 정리는 CPU 코어는 1개라는 가정을 하였다.
CPU 코어가 여러개 일 때 스케줄링은 어떻게 하는지 고민을 해봐야한다.
CPU가 여러개 인 경우 동시에 여러개의 작업을 병행하여 실행할 수 있다. 이는 load sharing이 가능하도록 한다. 각 CPU 코어들이 협업하여 작업들을 나누어 실행하여 전체 작업을 빠르게 수행할 수 있는 환경을 구성해줄 수 있는 OS 스케줄링이 필요하다.
그 중에서 load sharing을 하기 위해서는 어떤 방법이 있을까?
● 방법1: 비대칭 다중 처리(Asymmetric multiprocessing)
스레드(해야할 작업이)가 많다고 가정해보자. 이를 t1, t2, t3, ...라고 하자.
그리고 core1, core2, ... core_n이 있을 때 각 스레드들을 코어에 할당하기 위해서는 누군가 이런 작업을 해주는 사람이 있는데 코어 중 하나를 선택해서 스레드를 CPU에 할당(스케줄링)해주는 역할을 담당할 수 있게 해준다.
-> 코어(core1, core2, ... core_n)중 하나를 선택해서 (예로 core3)은 스레드 혹은 작업들을 CPU(코어)에 할당해주는 스케줄링 역할을 담당한다고 해보자.
이 core3은 시스템 데이터 자원을 접근해서 data sharing을 담당해준다.
이처럼 비대칭 다중 처리는 오직 하나의 코어만 시스템 자로구조에 접근하여 자료 공유의 필요성을 배제하기 때문에 간단하며, 단점으로는 마스터 서버가 전체 시스템 성능을 저하할 수 있는 병목이 된다는 단점이 있다.
● 방법2: 대칭 다중 처리(Symmetric multiprocessing)
각각의 프로세서(core)는 스스로 스케줄링을 할 수 있다. 각 프로세서의 스케줄러가 준비 큐를 검사하고 Run 할 스레드를 선택하여 스케줄링을 한다.
각 프로세서의 스케줄러가 준비 큐를 검사하고 실행할 스레드를 선택하여 스케줄링을 진행하는데 이는 스케줄 대상이 되는 스레드를 관리하기 위한 두 가지 전략을 제공한다.
① 전략1: Common ready queue
모든 스레드가 공통 준비큐에 있을 수 있다. ->공유 준비 큐에서는 경쟁 조건이 생길 수 있고 이로부터 공통 준비큐를 보하하기 위해 locking 기법의 하나를 사용할 수 있다.
즉 여러 코어가 동시에 같은 스레드를 실행시키는 것을 막는 locking 기법을 사용한다.
큐에 대한 모든 엑세스에는 lock 소유권이 필요하기 때문에 locking은 매우 경쟁이 심할 것이고 공유 queue는 성능의 병목 현상이 될 수 잇다.
이 방법의 단점은 스레드의 대기 시간이 길어지며 같은 데이터(공유 데이터)를 스레드들이 공유할 때 치명적인 문제가 발생한다. 따라서 per-core run queue 방법이 고안됨
② 전략2: per-core run queue
각 프로세서(core)가 자신만의 실행 큐에서 스레드를 스케줄 할 수 있도록 허용한다.
자신만의 프로세스별 queue가 있으면 캐시 메모리를 보다 효울적으로 사5용할 수 있다.
이 방법은 load balancing을 맞추는 작업이 필요하다.
● load balancing이란?
대칭 다중 처리(Symmetric multiprocessing) 에서는 각각의 프로세서(core)는 스스로 스케줄링을 할 수 있다. 각 프로세서의 스케줄러가 준비 큐를 검사하고 Run 할 스레드를 선택하여 스케줄링을 한다.
어떤 core는 처리할 queue의가 작고 어떤 core는 처리해야할 queue의 작업이 많을 수 있는다. 즉 core각각이 스스로 스케줄링하여 처리하는 queue가 있는데 이 queue들의 처리할 작업은 균등해야하는데 균등하지 못하는 경우가 있을 수 있다. 이러한 것을 load balancing이라고 한다.
load balancing을 할 때 테스크의 수가 같거나 각각의 테스크 작업을 실행하는 시간의 합이 같을 때 load balancing이 맞춰졌다고 말한다.
core1에는 2개의 tesk, core2에는 역시 2개의 tesk, core3에는 1개의 task, core4에는 4개의 task가있을 때 load balancing을 맞추기 위해 core4의 task를 core3으로 옮긴다고 해보자. 이러한 것을 task migration이라고 한다.
이 과정에서 그냥 옮기는 것이 아니다. 옮기는 과정을 설명하겠다.
현재 코어에서 실행중인 스레드를 종료하고 다른 스레드를 CPU로 가져왔을 때 어떤 문제가 있냐면
문제1 : flusing 문제
문제2 : 캐시 문제
스레드를 바꾼다면 캐시의 내용은 변경되기전 스레드의 지역성을 담고 있기 때문에 쓸모 없어지게 된다.
○ soft affinity
CPU가 될 수 있으면 기존의 수행했던 명령어를 계속 실행하도록 유도하는 것이다. os가 동일한 처리기에서 프로세스를 실행시키려고 노력하는 정책을 가지고 있는 경우 os가 될 수 있으면 그냥 하던 스레드를 수행하도록 유도한다.
즉 운영체제는 프로세스를 특정 core에서 실행시키도록 노력하지만 프로세스가 core 사이에서 이주하는 것이 가능하다.
○ hard affinity
특정 처리기에서 반드시 처리하도록 강요하는 경우가 있는데 이를말한다.
예를 들어서 리눅스에서 코어 하나를 선택하고 이 코어는 System Call 만 해결하라고 할 수 있다. 즉 정리하면 임의의 스레드가 있다고 해보자. 이 스레드가 Systsem Call을 담당한다고해보자. 이 스레드는 특정 처리기(core)에서만 run 되고 다른 처리기(core)로 이주가 불가능하다.
● NUMA and CPU Scheduling
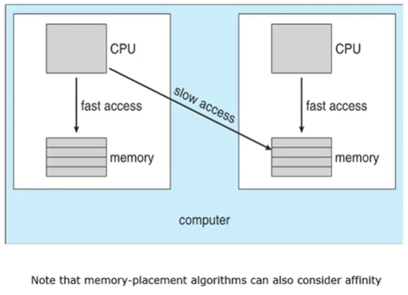
NUMA(Non-Uninform-memory-access) 라는 것은 스레드라고 하는 것은 스레들 별로 메모리를 공유하는데 같은 프로세스 안에있는 스레드들이 다른 CPU 코어에서 동작하는데 메모리는 스레드별로 공유할 수 있기 때문에 당연히 t1필요한 메모리의 내용이 t2가 실행하는 CPU의 메모리에 있을 수 있다. 이것은 t1이 t2 메모리에 접근하는데 시간이 느리기 때문에 slow access라고 하고 t1이 필요한 메모리의 내용이 해당 core 에 있는 메모리에 접근하는데 이는 fast access라고 한다.
스레드를 어떤 프로세서에서 다른 프로세서로 옮기는 작업은 많을 것을 고려해야하는데 이는 굉자히 복잡한 os의 구현이 필요하다. 결론적으로 동일한 프로세서에서 스레드를 계속 실행하면 캐시 메모리 또는 데이터를 사용할 수 있는데 load balancing을 위해 스레드를 다른 프로세서로 옮기는 것은 위에서 언급한 flushing 문제, 캐시 문제 등 유발한다.
따라서 이러한 굉장한 주의가 필요한 것은 OS의 복잡한 구현이 필요한 것이다.
● load balancing을 구현하는 방법 2가지
○ Push migration, Pull migration
core1의 작업이 core2보다 더 많을 때 core2는 core1의 스레드 작업을 pull 한다.
이에 따라 core1는 본인의 스레드를 core2에게 pull 해줘야한다. 이렇게 load balancing이 맞춰지며는 것을 push(pull) migration이라고한다.
다시 정리하면, push migration에서는 특정 스레드가 주기적으로 각 core의 부하를 검사하고 만일 불균형 상태로 밝혀진다면 과부하 core에서 쉬고 있는 coer에게 스레드를 이동(push)함으로써 load balancing을 맞춘다.
반대로 pull migration은 쉬고 있는 core가 바쁜 core를 기다리고 있는 프로세스를 pull(당기다)할 때 일어난다.
3) 다중 코어 프로세서(Multicore Processors)
● Multithreadyed Multicore System
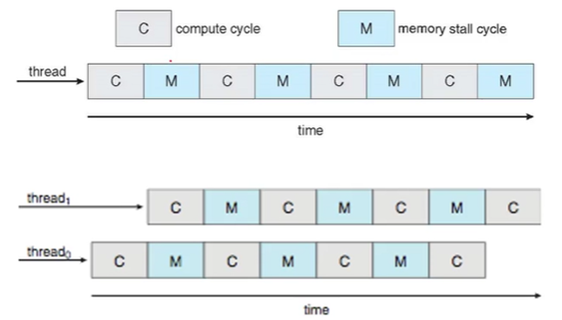
memory stall문제란 프로세서가 메모리에 엑세스 하여 fetch 할 때 이 데이터를 읽어오기 까지 굉장히 오랜 시간이 걸린다. -> memory stall
즉 CPU burst를 하다가 I/O 작업이 발생해 메모리로부터 값을 읽어오는 동안 CPU는 논다는 것이다.
다시 말해, 메모리에서 CPU burst를 통해 CPU 작업을 하는데 I/O작업이 발생해? -> 그럼 CPU는 그때부터 놀게 된다. (위 이미지 중 첫 이미지)
이때 프로세스 스케줄링 같은 경우는 다른 프로세스를 실행하여 CPU가 놀지 않도록 하면 되는데 스레드일 경우 다른 스레드로 바꾸는 것은 -> 쉬운 작업이 아님
스레드간에 Context Switching이 자주 일어나면 효율성이 떨어진다.
이 문제를 해결하기 위해 위 이미지 중 두 번째 이미지를 보자.
CPU에 채널을 두 개 두는 것이다. 하나의 코어에 두 개 이상의 스레드가 할당된다.
따라서 두 개 이상의 스레드가 교차로 실행될 수 있도록 만들어준다.
스레드0가 CPU burst를 실행하다가 I/O burst가 발생하면 다른 스레드(스레드1)을 실행한다. 이것이 가능한 이유는 스레드0, 스레드1은 같은 프로세서이기 때문에다.
즉 같은 프로세서 내의 스레드간에는 메모리 공유가 가능하기 때문에 하나의 스레드0을 실행하다 다른 스레드1을 바로 실행할 수 있고 이와 같이 채널을 두고 교차로 실행하는 방식을 chip multi-threadyig, CMT 라고 하며 이를 칩 다중 스레드라고 부른다.
'전공 > 운영체제' 카테고리의 다른 글
| Chapter5 실시간 스케줄링 (0) | 2022.06.27 |
|---|---|
| Chapter5 프로세스 스케줄링(Multilevel Queue, Multilevel Feedback Queue ) (0) | 2022.06.27 |
| Chapter5 프로세스 스케줄링(Multilevel Queue Scheduling Algorithm을 위한 여러가지 알고리즘) (0) | 2022.06.27 |
| Chapter4 Thread (0) | 2022.06.27 |
| Chapter3 Process (0) | 2022.05.05 |