목차
1. 프로세스의 개념
2. 프로세스의 상태
3. 프로세스의 상태 정보는 어디에 기록하나? (PCB)
4. Schedulers
5. Context Switch
6. 프로세스의 생성
7. 프로세스의 종료
8. 프로세스 간의 통신 - IPC(Interprocess communication)
9. Remote Procedure Calls
10. Pipes
1. 프로세스의 개념
프로세스이란 무엇인지 프로세스의 스케줄링, 프로세스 간의 communication을 살펴본다.
프로세스는 공유 메모리 또는 메시지를 통해서 통신이 이루어진다.
1) 시분할의 개념
HDD에 있는 프로그램이 실행되면 메인 메모리에 load 되어 프로세스가 된다.
하지만 모든 프로세스가 실행 상태를 가지는 것이 아니라 CPU등 하드웨어 자원을 os로부터 받아야 실행 프로세스가 된다.
컴퓨터에서 불리던 작업에서 시분할 시스템이라고 불리는데 시간을 공유해서 실행되는 시스템인데 컴퓨터라고 하는 것이 만들어진 목적이 여러 가지 작업을 동시에 수행할 수 있는 시스템으로 변모하기 시작했다. 이것을 멀티 테스킹이다 라고 한다.
프로그램이 해야하는 작업을 아주 잘게 쪼개어 프로세스 간에 문맥 교환이 이루어지게 된다.
cpu(싱글 코어)에서 하나의 프로그램이 동시에 실행되는 것이 아니라 시간을 쪼개어 쪼개진 시간에 프로그램들을 조금씩 실행시키게 되는데 이것이 시분할의 개념이다.
2) 프로그램의 구조(text section과 data section)
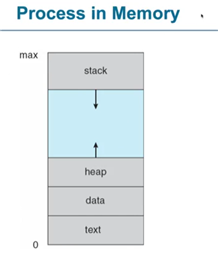
프로그램의 구조는 크게 text section과 data section으로 나뉜다.
프로그램을 짤 때 모드 text로 짠다. 프로그램 소스코드는 text section이라고 하고 그 코드 안에서 전역 변수의 값과 같이 프로그램이 실행되는 동안 필요한 데이터를 data section이라고 한다.
다시 정리하면
text는 cpu가 프로그램을 통해 실행하는 것
data는 cpu가 프로그램을 실행하는 동안 필요한 데이터
추가로 heap영역은 프로그램 실행 중에 동적을 할당되는 메모리이다.
스택 영역은 함수를 호출할 때 임시 데이터 저장장소이다.
(함수의 매개변수, 복귀 주소, 지역 변수)
프로그램이 실행되면 프로그램의 소스코드를 위와 같은 형태로 ram에 올린다.
우리의 프로그램 코드는 text section에 저장되고 전역 변수와 같이 프로그램이 실행되는 동안 필요한 데이터는 data section에 heap은 객체 stack은 메소드의 프레임이 할당되는 공간이다.
stack은 함수가 호출될 때마다 stack이 위에서 아래로 자라게 된다.
stack은 max즉 상위 주소에서 하위 주소로 자란다.
A가 caller이고 B가 callee 일 때 A에서 사용했던 변수들을 stack에 저장한다. B라는 함수가 또 C를 호출하면 B의 로컬 변수들을 stack 에 저장한다.
3) Programms / Process
프로그램이라고 하는 것은 2진 형태의 데이터의 집합이다. dormant라고 하는데 이는 아직 동작을 시작하지 않았지만 실행될 수 있는 상태를 말한다.
프로그램이 실행된다고 하는 것은 HDD에 저장되어 있는 프로그램이 process 형태로 바뀌는 것이다.
그럼 왜 프로그램은 2진 형태로 존재해야하는가?
=> 프로그램이 메인 메모리에 적재되었다고 모두 실행되는 것이 아니다.
그럼 어떤 프로세스가 현재 실행 중이다 애기할 수 있냐면 CPU 자원을 할당 받았을 때만 프로세스가 실행되는 것이다.
메인 메모리에 적재된 명령어 중 CPU 자원을 할당 받지 않는 명령어는 sleep 한다라고 한다.
프로세스 A를 실행하다가 잠시 멈추고 프로세스 B에게 자원을 할당한다고 해보자.
그럼 프로세스 A는 sleep mode로 들어간다. CPU 자원을 최대한 할당할 수 있는 시간이 정해져있다.
특정 시간이 되면 CPU 자원은 다른 프로세스로 할당을 넘겨야한다.
정리=>
Process는 언제나 Running Program이 아니다. CPU 자원을 할당 받았을 때만이다.
★ create Process는 HDD-> RAM으로 load 하는 작업을 말한다. ★
★ run Process는 CPU 자원을 할당 받았을 때 실행시킬 때를 말한다. ★
프로세스에 대한 정보(사용자, 사용자 정보와 연계된 프로세스 등..)도 커널에서 가지고 있다.
우리가 만든 프로그램은 프로세스에게 할당된 파일들이 있다.
그리고 프로세스는 프로세스를 실행한 사용자 정보도 가지고 있다.
그리고 스레드에 대한 정보도 가지고 있다.
4) Process ID
프로세스를 관리하기 위해서는 프로세스를 특정할 수 있어야한다.
PC에서 실행되는 모든 프로세스는 ID를 가진다. ID는 현 시점에서 컴퓨터에서 실행되는 모든 프로세스간에는 ID 값이 서로 Unique하다.
즉 오늘 실행한 프로세스 A가 할당 받은 ID가 내일 실행할 프로세스 A의 ID와 다를 수 있다.
PID라고 하는데 PID 0번은 만약 컴퓨터가 시작되고 프로세스가 0개라면 (사용자도 os도 없음)
이때 스스로 무엇인가를 반드시 실행해야하는데 이 무엇인가에 해당하는 것이 idle process이며 이것의 PID는 0이다.
그럼 PID가 1번은 init process이다. 커널이 부팅을 한 다음에 커널이 실행하는 최초 프로세스이다.
| 1. /sbin/init |
| 2. /etc/init |
| 3. /bin/init |
| 4. /bin/sh |
커널이 부팅하면 1번 프로세스를 먼저 찾고 실행하는데 만약 1번 프로세스가 없으면 2번 프로세스를 찾아서 실행한다. 만약 2번도 없으면 3번을 3번도 없으면 4번을 찾아 커널의 최조 프로세스로 실행을 한다.
PID를 저장하는 값은 pid_t라는 값이 있다. 프로그램 측면에서 PID는 pid_t 타입에 저장하는데
이것이 정의된 헤더 파일은 <sys/types.h> 이다.
#include <sys/types.h>
#inlcude <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
printf("My pid=%jd\n", (intmax_t) getpid());
pritnf("Parent's pid=$jd\n", (intmax_t) getppid());사실 리눅스에서 pid_t는 int typde임 위 함수는 현재 실행되고 있는 프로세스의 PID를 가져올 수 있다.
두 번째 getppid 메소드는 현재 실행되고 있는 프로세스의 부모 프로세스의 PID를 가져온다.
출력할 때는 위 방법을 사용한다.
5) Process ID Allocation
Process ID는 프로세스가 할당 될 때 마다 마지막에 할당된 프로세스 ID 다음의 ID를 할당해준다. 즉
Process ID는 linear 하게 증가한다. (0,1,2,3,4....)
예를 들어 ProcessA->ProcessB->ProcessA종료->ProcessC라고하면
Process ID 할당은 ProcessA(PID: 1번)->ProcessB(PID: 2번)->ProcessA종료->ProcessC(PID: 3번(1번 할당x)) 이렇게 할당한다.
그리고 만약 PID가 /proc/sys/kernel/pid_max에 도달하면 어디로 가냐? 1번 할당을 준다.
즉 프로세스의 종료로 낱알이 빈 PID를 다시 순차적으로 부여한다.
6) Executing a Program / Creating a New Process
● Executing a Program(프로그램 실행)
Executing a Program이란 즉 프로그램을 실행하는 것은
★ create Process는 HDD-> RAM으로 load 하는 작업을 말한다. ★
★ run Process는 CPU 자원을 할당 받았을 때 실행시킬 때를 말한다. ★
위 두 과정을 진행하는 것을 말한다.
● Creating a New Process
기존에 RAM에 존재하는 프로세스 (부모 프로세스)가 새로운 자식 프로세스를 실행하는 것을 말한다.
아주 가끔은 새로운 프로세스가 새로운 프로그램을 실행하는 경우가 있다.
자세히 설명하면
기존의 프로세스A가 1부터 10까지 명령어가 실행된다고 해보자.
5라는 구간은 fork() 이다.
그럼 6부터 10까지를 duplication하여 다른 새로운 프로세스B로 실행시키는 것을 말한다. (fork 과정)
A와 B는 부모와 자식 관계로 존재한다.
이때 6부터 10 사이에 execl() 라는 코드가 있다고 가정하면 프로세스 B는 (자식 프로세스) execl()를 만나는 순간 프로세스 B의 RMA을 모두 비운다. 그리고 exec()가 실행하고 하는 새로운 프로그램을 그 지운곳에 적재하고 실행을 한다.
이때는 부모 프로세스 A와 자식 프로세스 B(지금은 execl()에 의해 적재된 새로운 프로세스임)의 내용은 달라진다.
2. 프로세스의 상태
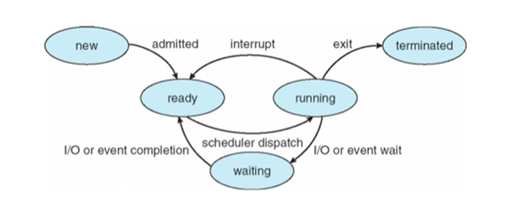
여러 프로세스르 CPU가 시분할 시스템을 즉 멀티 테스킹으로 실행하기 위해서는 프로세스는 이와 같은 적절한 상태를 가져야한다. 프로세스의 상태를 변경하는 것은 os가 담당한다.
● new
프로그램을 더블클릭하는 것이다
● running
프로세스의 text section에 있는 것이 cpu에 들어가는 것이 running 상태이다.
즉 ram에 있는 프로세스가 cpu자원을 할당받고 실행되는 상태이다.
이 상태에서 프로세스의 IO작업이 발생해야한다면 IO작업을 하기 위해 sleep이 되고 os는 CPU등 자원을 다른 프로세스에게 할당한다. (IO작업이 일어나면 sleep 한다)
● wating
프로세스가 어떤 이벤트가 일어나기를 기다린다. (예를 들어 부모가 자식이 죽기까지 기다림)
● ready
A프로세스의 IO작업이 끝낫다는 신호를 받으면 A는 read 상태가 되어 CUP가 할당되기만을 기다린다.
● terminated
프로세스의 종료
3. 프로세스의 상태 정보는 어디에 기록하나? (PCB)

각 프로세스는 OS에서 Process Control Block 이라는 PCB라는 곳에 프로세스의 state 정보를 저장한다.
PCB에는 프로세스의 번호, 프로세스 상태, PC정보, 프로세서의 레지스터 값들, 메모리의 경계, 프로세스가 사용했단 파일 등 정보들을 담고 있다. 즉 PCB block은 회계 데이터와 함께 프로세스를 시작시키거나 다시 시작시키는데 필요한 모든 데이터를 위한 저장소의 역할을 한다.
프로세스 스케줄러는 코어에서 실행 가능한 여러 프로세스 중에서 하나의 프로세스를 선택한다. 각 CPU의 코어는 한 번에 하나의 프로세스를 실행할 수 있다.
즉 다중코어 시스템에서는 한 번에 여러 프로세스를 실행할 수 있다.
일반적으로 대부분의 프로세스는 “I/O 바운드 프로세스”, “CPU 바운드 프로세스” 두 가지로 설명이 된다. 전자자는 IO작업이 많은 프로세스이고 후자는 CPU 계산이 많고 IO 작업이 적은 프로세스를 말한다.
PCB라는 것은 양방향 링크드 리스트로 구성되어 있는데 이것을 저장하고 있는 곳은 queue이다.
프로세스를 관리하기 위한 Queue가 여러개 있는데 그 중 하나가 Job Queue이다.
아래와 같은 프로세스를 관리하기 위한 여러 Queue가 존재하는데
프로세스는 아래의 Queue를 이동한다. 즉 각 프로세스의
PCB 정보가 아래의 여러 Queue들을 통해 상태정보를 갱신한다.
● Job Queue
현재 시스템에서 실행되고 있는 프로세스의 정보를 담고 있다
● Read Queue
read 상태의 프로세스 정보를 담고 있다. 프로세스가 시스템에 들어가면 준비큐에 들어가서 준비 상태가 되어 CPU 코어에서 실행되기를 기다린다. 이 큐는 일반적으로 연결 리스트로 저장된다. 준비큐 헤더에는 리스트의 첫 번째 PCB에 대한 포인터가 저장되고 각 PCB에는 준비큐 다음 PCB를 가리키는 포이넡 필드가 포함된다.
● Device Queues(Wating Queue를 말한다.)
IO device의 사용으로 wating하고 있는 프로세스이다.
왜 Device Queues는 복수일까? (Queue X/ Queues O)
컴퓨터 디바이스마다 Queue가 있기 때문이다.
즉 프로세스가 IO작업을 하기 위해 기다리는 공간으로 wating하는 프로세스의 PCB를 담는 Queue가 있을 수 있고
NIC 카드를 사용하기 위해 wating하는 프로세스의 PCB를 담는 Queue등이 있기 때문이다.
※ time slice의 개념
프로세스에서 interrupt 또는 System call 등이 없어 즉 ready 될 일이 없으면 계속 실행되냐? 아니다. 프로세스가 최대로 실행될 수 있는 시간을 time slice라고 하는 곳에 저장한다. 최대 시간이 지나면 read Queue에 PCB 정보를 삽입하고 다른 프로세스를 실행시킨다.
4. Schedulers
● Short-term scheduler
Read Queued에 존재하는 프로세스 중 어떤 프로세스를 running 시킬지 결정한다.
CPU 자원을 실제로 할당 함으로써 실행이 되는데 CPU자원을 프로세스에게 할당하는 것은 운영체제가 할 일이다.
OS 스케줄러라고 하면 일반적으로 Short-term 스케줄러를 의미한다.
● Long-term scheduler
이것은 보통 jop 스케줄케줄러라고도 하는데 어떤 프로세스를 read queue에 넣을지 결정하는 역할을 한다.
코어가 하나인 CPU를 멈춰서 보면 무엇이 실행되고 있는지 보면
CPU는 하나의 c소스코드로 작성된 코드를 여러개의 스레드로 분할하여 실행한다.
즉 CPU는 멀티 작업을 하며 하나로 작성된 코드를 여러 스레드로 분할하여 동시에 실행한다. (즉 소스코드를 두 개로 분리한다.A와 B로 분리하겠다고 하겠음) 이렇게 분리된 소스코드는 멀티로 실행되다 if문 과 같은 문을 만나면 다시 하나로 모인다.
이와 같이 Job을 분리하고 어떤 Job을 먼저 read Queue에 넣을지 판단하는 것이
Long-term scheduler라고 한다.
프로세스가 if문에서 갈리지 못하고 걸리게 되는데 A라는 작업과 B라는 작업이 나뉘어 동시에 실행되는데 if문에서 걸라지 못하고 걸리게 된다.
만약 A라는 작업보다 B라는 작업이 더 짧다면 B는 A보다 먼저 끝나서 기다리게 되는 현상이 발생한다 즉 CPU가 놀게 되는 현상이 발생한다.
CPU의 연산이 느려지게 되는 가장 큰 이유 중에 하나는 조건문 때문에 느려지는 것이다.
CPU는 컴퓨터 아키텍쳐 구조로보면 스핀은 굉장히 빠르나 IO 작업 및 조건문 작업을 만나게 되면 CPU의 속도가 느려지게 된다. 즉 CPU의 성능의 하락을 가져온다.
최근 CPU에서는 if문은 if문대로 else문은 else문 대로 둘다 실행을 한다.
A라는 작업이 B보다 (if문을 만나기 전까지) 끝나는 속도가 느리기 때문에 A라는 작업이 끝날 때 그때 if문과 else문 중 하나를 버리는 방식을 택하여 CPU가 노는 시간을 방지한다.
CPU의 속도를 높이기 위해서는 OS와 컴파일러의 협업이 없으면 이루어질 수 없다.
※ 프로세스의 종류에는 2가지 있다.
1) IO Bounded Process
IO 작업이 많은 프로세스
2) CPU Bounded Process
CPU 계산 작업이 많은 프로세스
● Medium-term scheduler
스와핑을 한다. 메모리에 올라와 있는 프로세스가 너무 많아 줄여주는 역할을 하거나 반대로 메모리에 올라온 프로세스가 너무 적어 프로세스를 올려주는 그런 Swaping역할을 한다.
예를 들어 if문에 해당하는 명령어를 실행하는 부분과 else문이 있으면 이 둘을 메모리에 모두 올리고
이 둘 중 필요 없는 결과값이 생기면 그를 버리고 다른 프로세스를 올리는 것의 역할을 하는 것이 Medium-term scheduler의 역할이다.
5. Context Switch
● Context Switch
CPU가 프로세스에게 자원이 할당된 상태에서 다른 프로세스로 CPU 자원이 넘어가는 것을 말한다.
즉 나(CPU)가 수학(프로세스1) 공부를 하다가 영어(프로세스2) 공부로 넘어가는 작업이 Context Swtich이다.
Context Switch가 자주 일어나면 역시 CPU가 노는 시간이 늘어남을 의미한다.
Context Switch을 하는 동안 CPU는 논다.
(비유를 하면 내가 수학 책을 덮고 영어책을 펼치는 작업은 내(CPU)가 일을 했다고 하지 않는다.)
Context Switch가 일어날 때 A에서 B로 전환이 일어날 때 A프로세스의 상태 정보를 어딘가에 기록을 해놔야한다. 그래야 A가 다시 자원을 받고 실행할 때 전에 실행했던 다양한 상태 정보를 가지고 와서 실행하 수 있기 때문이다.
Context Switch란 프로세스의 PCB(Proces Control Block) 정보를 교체하는 것이다.
이전의 프로세스 상태는 보관 새로운 프로세스의 상태를 복구
OS가 복잡하거나 PCB가 복잡할 수 록 Context Switch를 하는데 시간이 오래걸린다.
프로세스 관리라고 하는 것은 프로세스를 생성하고 종료하는 것을 말한다.
6. 프로세스의 생성
● 부모 프로세스란
프로세스들은 내부적으로 트리 형태로 구성되어 있다.
프로세스는 PID라는 것을 통해 구분이 된다. 즉 모든 프로세스는 자신만의 숫자로 된 PID를 가지고 있다. 부모와 자식 간의 프로세스는 모든 리소스를 공유한다.
또한 자식 프로세스는 부모 프로세스의 자원을 일부 공유한다.
부모는 자식 프로세스의 리소를 공유하지 않는다. (상속의 개념)
실행 옵션이란?
부모와 자식 간에 프로세스가 동시에 실행될 수 있고 (동시에 실행되는 것처럼 보임)
부모 프로세스는 자식 프로세스의 종료까지 기다리는 경우도 있다.
init이라고하는 PID 가 1인 프로세스가 있다. 이는 최상위 프로세스로 컴퓨터가 부팅되면 생성된다.
● fork(코드1)
프로세스가 실행되는 동안 프로세스는 여러 개의 새로운 프로세스들을 생성할 수 있다.
주소공간 얘기인데 자식 프로세스가 부모 프로세스의 정보를 그대로 받아들일 수도 있고 자식 프로세스는 새로운 프로세스를 실행 시킬 수 도 있다.
즉 부모 프로세스가 자식 프로세스를 낳았는데 이 부모와 자식이 하는 일이 같을 수도 있고 다를 수 도 있다 (fork 시스템 콜의 개념)
#include <sys/types.h>
#incldue <stdio.h>
#include <unistd.h>
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
fprintf(stderr, “fork 실패”);
return 1;
} //fork 에러
else if(pid ==0) {
execlp(“/bin/ls”, “ls”, NULL);
} //자식 프로세스의 내부임
else {
wait(NULL);
printf(“Child Compolete”);
} //부모 프로세스의 내부로 자식이 끝나 때까지 기다림
reutrn 0;
}
7. 프로세스의 종료
● exit()
프로세스의 종류는 exit()이라는 시스템 콜을 호출함으로써 현재 진행중인 프로세스가 종료된다. 자신을 나은 부모 프로세스에게 상태 값을 전달한다. 부모 프로세스는 wait이라는 함수를 통해 자식 프로세스로부터 해당 상태 값을 반환받을 수 있다.
프로세스가 종료되면 해당되는 리소스(CPU, 메모리 자원 등)을 운영체제에게 돌려주게 된다.
● abort()
○ 부모 프로세스는 abort()라는 시스템 콜을 사용해서 자식 프로세스를 강제 종료시킬 수도 있다.
자식 프로세스가 할당된 자원의 범위를 넘어갈 때 (다른 프로세스가 사용하는 메모리를 참조한다던지, 자식 프로세스가 더 이상 수행할 일 이 없을 때 등등) aobrt()라는 시스템 콜을 사용해서 자식 프로세스를 중지시킬 수도 있다.
○ 부모 프로세스가 종료되면 자연스럽게 자식 프로세스도 종료되는 것이 일반적이다. 하지만 부모 프로세스가 종료되며 자식도 종료되야하는데 그렇지 못한 경우 abort()를 사용해서 자식을 종료할 수 있다.
● cascading termiation
부모 프로세스가 실행되다 자식 프로세스를 낳고 자식이 또 자식을 낳은 경우 부모 프로세스가 종료되면 자연스레 그 하위 자식 프로세스는 연속적으로(cascading) 하게 자식들이 종료되야한다는 개념이다.
cascading termiation은 운영체제에 의해 실행된다.
● wait()
부모 프로세스가 자식 프로세스를 하나 생성하였다. 그럼 부모 프로세스는 자식 프로세스가 종료될 때 까지(자식 프로세스에서 exit()를 부를 때 까지) 기다리고
자식 프로세스가 종료되면 자식 프로세스에서 상태 정보를 부모 프로세스에게 전달한다.(status에 기록한다.) 전달하는 방법을 보면
wait함수는 매개변수로 status라는 변수의 주소 값을 매개변수로 지정한다.
status는 부모 프로세스의 변수이고 이 주소를 자식 프로세스에게 전달하는데 자식 프로세스에서 이곳에 기록을 하면 부모 프로세스에게 정보를 전달할 수 있다는 것이다.
● 좀비 프로세스
부모 프로세스가 wait를 하지 않는다. 즉 기다리지 않는다.
어떤 부모 프로세스도 waitng을 하지 않는 상태이다. 근데 이게 고아 프로세스랑 헷갈릴 수 있는데
부모 프로세스가 실행하다가 fork(자식 프로세스를 낳았다)를 했다. 그리고 일을 진행하다
부모가 wait()이 되기전에 자식 프로세스가 종료가 된 것이다.
즉 wait으로 부모 프로세스가 자식이 죽기 전까지 기다렸다가 자식이 죽으면 상태 정보를 statis에 저장하는 구조인데
부모가 wait을 호출하기도 직전에 자식 프로세스가 죽어서 죽은 자식 프로세스의 상태 정보를 부모 프로세스에 기록할 수 없는 상태를 말한다.
그럼 부모 프로스세스에서 wait을 만나면 좀비 프로세스에서 죽은 자식 프로세스의 상태 정보를 얻고 나 후 좀비 프로세스는 종료되게 된다.
● 고아 프로세스(orphan)
부모가 자식 프로세스를 낳고 자기 할 일을 하고 종료하는 것이다.
즉 부모가 먼저 죽은 것이다. 이런 경우 부모 프로세스가 종료되 후에도 자식 프로스세가 동작할 때 이 자식 프로세스를 고아 프로세스라고 한다.
8. 프로세스 간의 통신 - IPC(Interprocess communication)
프로세스 간에는 통신이 되도록 설계가 되어 있는데 독립적이지만 서로 상호간에 협력을 할 수 있다.
상호 협력을 한다는 것은 둘 간에 통신을 기본으로 한다. cooperation(협력) 즉 독립적인 프로세스간에 소통을 할 수 있는 환경을 제공한다.
프로세스가 협력하는 이유는 정보를 공유하거나 프로세스간에 병렬 연산을 통해 계산 속도를 높이이는 등의 이유가 있다.
조별 과제를 비유하면 누구는 주제 선정, 자료 조사, 발표, ppt(모듈화=> p1, p2... 프로세스임) 등 이렇게 조를 구성(조 == 프로세스)하는데 모듈화들은 각각 서로 통신을 해야함
1) IPC의 방식1 : Shared memory
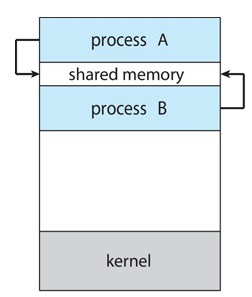
두 프로세스 P1, P2 사이에 (공유) 메모리라는 매개체를 둔다.
P1이 메모리에 기록을 한다. 그 다음 P2에서는 그 기록을 읽어간다. P2 도 write 작업을 공유 메모리에 적는다. 이처럼 일종의 게시판 역할을 해주는게 공유 메모리 방식이다.
● 여러 프로세스가 동시에 하나의 파일에 write를 하는 경우
공유 메모리를 만들고 이곳에 데이터를 기록한다.
이것의 중요한 점은 사용자 프로세스가 제어를 하고 os는 이에 관여하지 않는다.
● Procuder-Consumer Problem에서 notify는 os가 관여를 해야한다. (notify, sleep하는 것은 os가 하기 때문이다.)
여러 프로세스가 동일한 파일을 공유할 때(특히 write를 할 때) 문제가 발생한다.
실제로 위 프로세스들이 한 공유 파일을 모두 read하는 경우는 문제가 발생하지 않지만 한 프로세스라도 write를 할 때 문제가 발생한다.
=> 하나의 자원에 여러 프로세스가 동시에 write 하면 문제가 발생한다.
=> 한 프로세스만 write하고 나머지 프로세스는 읽기만하는데도 컴퓨터 입장에서는 문제가 발생한다.
p1, p2, p3 프로세스는 RAM안에서 본인의 메모리 공간 영역을 할당받는다.
그리고 세 프로세스에서 HDD 에 있는 파일을 동시에 open한다고 하면 이 HDD의 동일한 파일이 세 프로세스 버퍼에 3번 복사가 된다.
p1, p2, p3에서 write라는 IO작업을 하면(세 IO 작업은 파일의 서로 부분을 수정한다고 가정)
그리고 p1이 flush를 한 뒤 p2가 flush를 하면 HDD 입장에서는 p1이 작업한 내용에 p2가 작업 한 내용을 덮어쓰게 되는 것이다. (p1의 작업이 날아가는 문제가 발생한다.)
※ 문제점 해결 방법
위와 같은 문제점을 해결하기 위해
HDD에 파일이 우선 있다.
p1이 write mode로 open 했다. (p1이 RAM에 차지하고 있는 버퍼의 영역에 HDD-> RAM loading 작업함)
p1 write mode로 파일을 가져간다면 해당 파일은 잠근다. (Locking 한다.) 그래서 p1이 write가 끝나고 close 할 때까지 다른 p2 프로세스에서 locking된 파일을 read mode로 open 하지 못한다.
그럼 p2는 무엇을 하냐?=> p1이 close할 때까지 p2는 하던일을 멈추고 sleep 한다.
그리고 p1이 close를 하는 순간 운영체제가 sleep 하고있는 p2를 깨우고 p2는 open을 진행하게 된다.
※ write는 atomick operation이라고 하는데 write는 open된 시점부터 close될 때까지 누군가가 개입할 수 없다는 것을 의미한다. (5장에서 깊게 다룸)
2) IPC의 방식2 : Messgae passing
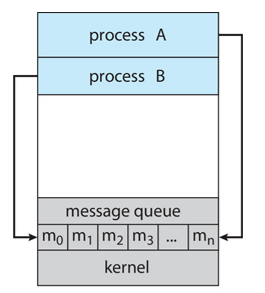
프로세스가 P1, P2 이렇게 있으면 프로세스 간에 메시지를 전달하고 메시지를 받는다..
메시지 큐라는 것이 있다. P1이 P2에게 전달하고 싶은 내용이 있으면 메시지 큐1에 그 내용을 넣는다. 그리고 P2는 메시지가 있다는 것을 보고 하나씩 읽어간다. (시간 날 때마다)
P2가 P1에게 하고 싶은 말이 있으면 메시지 큐2에 그 내용을 넣는다.
즉 메시지 큐가 프로세스 개수 만큼 필요한 개념이 된다.
3) bounded-buffer
원형 버퍼로 데이터를 저장할 수 있는데 정해진 개수 만큼 데이터를 저장할 수 있다.
(예로 10개) 즉 bounded-buffer는 버퍼의 개수가 제한된 것을 말한다.
Producer는 이 버퍼에 자기가 전달하고 싶은 내용을 체우는 거고 Consumer는 읽어오는 역할을 하고 이 두 작용은 독립적을 구성되어있다.
Procuder, Consumer 각각은 스레드로 만들어서 독립적으로 동작하는데 원형 큐가 Pull 상태 일 때는 Procuder는 잠시 멈춰야한다
① 원형 큐가 Pull인 경우
Pull 상태에서 Consumer는 데이터를 1개를 뺏다면 Procuder에게 notify를 해야한다.
즉 Pull 상태라면 Procuder는 더 이상 sleep 하여 원형 큐에 데이터를 넣지 않는데 이 상태에서 Consumer가 데이터를 하나 뺏다면 Consumer -> Producer에게 notify를 해줘야한다.
② 원형 큐가 empty인 경우
그럼 Consumer가 sleep하고 Procuder는 데이터를 1개 넣으면 Consumer를 notipy 한다.
● unbounded-buffer
버퍼의 사이즈에 제한이 없다. (마치 무한정 존재하는 자원처럼 사용하는 버퍼)
그냥 데이터 계속 채우면 되고 Consumer도 계속 읽으면 됨
9. Remote Procedure Calls
● 무엇인가?
클라이언트 시스템에서 함수를 보자 함수에는 Caller Callee가 잇는데 함수 간에 통신은 파라미터(매개변수)로 이루어지는데 A가 B를 호출하는데 두 함수가 같은 시스템에 있으면 상관없는데 만약 두 함수가 다른 시스템에(네트워크를 통해 연결되어 잇음) 존재할 때 이러한 경우의 호출 관계를 Remote Procedure Calls이라고 한다.
이 경우에 A에서 사용하던 변수등을 B의 파라미터(매개변수로) 전달을 해줘야하는데 이는 네트워크를 통해 전달해줘야한다. 그리고 B라는 함수의 리턴 값을 다시 네트워크를 통해 A로 전달해줘야한다.
10. Pipes
● 뜻
두 개의 프로세스 사이에 값을 전달해줄 수 있는데 리눅스에서 두 개의 명령어를 실행하기 위해 A | B 기호를 사용해 A라는 명령어의 결과 값을 B라는 명령어에 입력값으로 넣는 방식을 파이프라고 한다.
A라는 명령어와 B 명령어 간의 통신이 가능해지는 것이다.
보통은 A프로세스가 출력하는 값이 B 프로세스의 입력 값이 되지 않아도 되는 경우가 많음
파이프의 종류에는 아래 2가지가 잇다.
● 파이프의 종류1 : Ordinary pipes
Ordinary pipes란 단방향 통신이며 부모 자식 관계의 통신을 위한 개념이다.
다른 프로세스는 이들간의 통신을 방해(접근)할 수 없다.
producer가 한쪽에서 write하고 consumer가 다른 쪽에서 read한다.
● 파이프의 종류2 : Named pipes
부모와 자식 간의 상관 관계 없이 통신을 할 수 있는 파이프를 말한다.
통신이 양방향이다.
여러 프로세스가 함께 사용할 수 도 있는 pipe이다.
유닉스 윈도우에서 활발히 사용되고 있다.
'전공 > 운영체제' 카테고리의 다른 글
| Chapter5 프로세스 스케줄링(Multilevel Queue, Multilevel Feedback Queue ) (0) | 2022.06.27 |
|---|---|
| Chapter5 프로세스 스케줄링(Multilevel Queue Scheduling Algorithm을 위한 여러가지 알고리즘) (0) | 2022.06.27 |
| Chapter4 Thread (0) | 2022.06.27 |
| Chapter2 운영체제 개요2(OS의 구조) (0) | 2022.05.05 |
| Chapter1 운영체제 개요1 (0) | 2022.05.05 |