실험 주제 : 마스크를 올바르게 착용하였는지 검출하는 딥러닝
1.실험 내용 설명
Teachable Machine을 사용하여 사람이 마스크를 올바르게 썼는지(클래스1), 턱마스크를 하였는지(클래스2), 마스크를 미착용하였는지(클래스3) 검출하는 모델로 완전 연결층학습을 통해 딥러닝 모델을 만듭니다. 에포크의 값은 50으로 지정, 배치의 크기는 16, 학습률은 0.001로 처음 지정하여 모델을 만들었습니다. 이후 이 값들을 변경해 가며 딥러닝 모델이 얼만큼 테스트 데이터를 올바르게 검출하는지 실험을 하고 이를 분석하겠습니다.
학습용 데이터의 종류(feature)로는 총 3가지의 클래스가 사용됩니다.
마스크 착용, 턱마스크, 마스크 미착용 사진을 여러 각도와 다른 배경화면을 주어 각각 10장식 사진 촬영을 하여 학습 데이터로 사용하였습니다.
2. 티처블 머신 학습 이미지와 테스트 데이터 결과
● 각 테스트 데이터별 Teachable Machine 결과
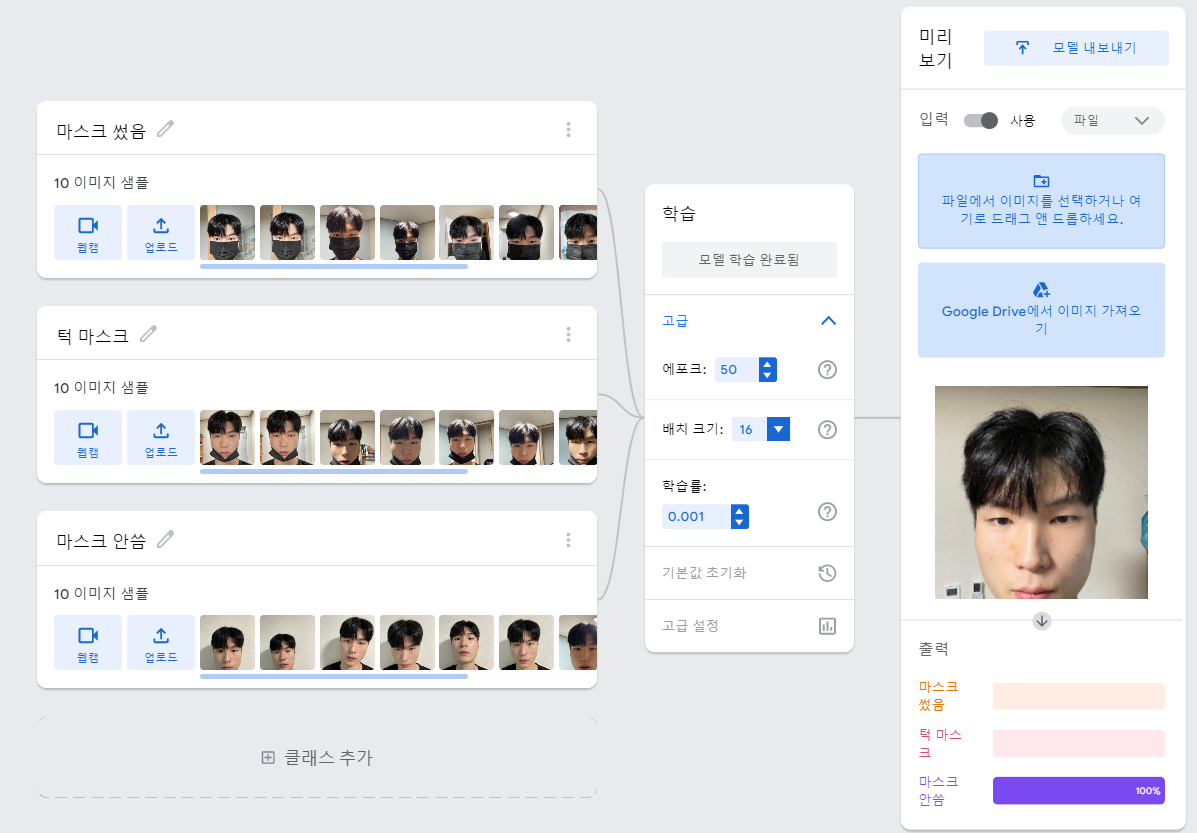


위 3가지 클래스(각각 10장의 데이터)로 딥러닝 모델을 만드는데 85%는 학습용 데이터 15%는 검증 데이터로 사용된다. 모델의 클래스별 정확도 및 혼동 행렬을 구했을 떼 85%의 학습용 데이터만으로 15%의 검증 데이터를 거의 100%에 가까운 정확도로 분류하였으며, 에포크별 손실 역시 0에 수렴하는 것을 확인하였습니다. 마스크를 안쓴 테스트 이미지는 99%, 턱마스크 이미지는 94%, 마스크를 쓴 이미지는 100%의 정확도로 테스트 데이터를 분류합니다.
3. 결과 분석
● 배치의 값을 변경하였을 때 학습에 미치는 영향
역전파 알고리즘 내용을 보면 하나하나 입력에 대해 가중치를 수정해 나가는 알고리즘을 설명하는데 이렇게 하나하나 입력에 대해 가중치를 수정해 나가는 것은 매우 비효율적이다. 따라서 배치라는 하나의 (데이터)묶음을 만들고 하나의 배치에 대해 오차를 한번에 계산한다. 위 실험의으로 배치의 값을 일정 값보다 작게한다면 모델의 정확도는 떨어질 것이다. 반대로 배치의 크기를 무작정 크게 하는 것 역시 학습의 정확도를 오히려 낮춘다. 따라서 배치를 적당히 나누는 것으로 첫 배치의 손실을 최소화 하도록 한다.
첫 배치에서 오차의 수정이 첫 배치에 대해서는 베스트였지만 두 번째 배치에 대해서는 좋은 수정이 아닐 수 있다. 따라서 두 번째 배치에 대해서 다시 첫 번째 배치에 대해 오차 수정이 다시 일어난다. 이러한 방법으로 딥러닝 모델을 학습하기 때문에 배치의 값을 너무 크지않게 지정해야하며, 배치의 값을 크지도 작지도 않은 적절한 값으로 설정하여 특정 배치에 대해 너무 의존적으로 학습을 하는 것을 막아야 한다.
아래 실험 결과를 보면, 배치의 크기가 16일 때 보다 256 일 때 애포크별 손실에서 학습의 오차는 상승하고 정확도는 떨어지는 것을 알 수 있다.
※ 이미지(첫 번째) : 배치 16, 이미지(두 번째) : 배치256


● 애포크의 값을 변경하였을 때 학습에 미치는 영향
애포크의 값을 50-> 100으로 변경하였을 때 역시 정확도는 떨어지고 손실을 증가하는 모델이 되었다. 전체 데이터의 수가 1만개 데이터가 있다고 할 때 배치의 크기가 100이라고 할 때, 1에포크 == 100번의 배치에 대해 역전파를 수행합니다. 즉 배치의 값을 매우 크게 증가시켰을 때와 같은 원리로 올바른 학습을 위해선 여러 에포크를 반복해야하지만 매우 큰 에포크 는 학습하는데 시간을 오래 걸리게 하며, 더 높은 성능을 보장하지는 않는다.
● 학습률의 값을 변경하였을 때 학습에 미치는 영향
학습률이 크면 -> 배치의 손실이 커졌다 작아졌다 하면서 올바른 학습이 되지 않을 가능성이 있지만 빠른 학습이 가능합니다. 학습률이 작으면 -> 학습의 속도는 느리지만 정밀한 학습이 가능해 집니다. 하지만 이는 local minimal이 발생할 수 있다는 문제점이 있습니다.
'전공 > 인공지능(입문)' 카테고리의 다른 글
| 2. OpenCV와 Raspberry Pi를 활용한 얼굴 인식 (0) | 2022.06.27 |
|---|